Skip to content
Tom Pepinsky
Tom Pepinsky
CV
Research
Books
Published Articles
Working Papers
Replication Data
Code
Collaborators
Teaching
Courses
PhD Students
Postdocs and Visiting PhD Students
Graduate Study at Cornell
Other
Blog
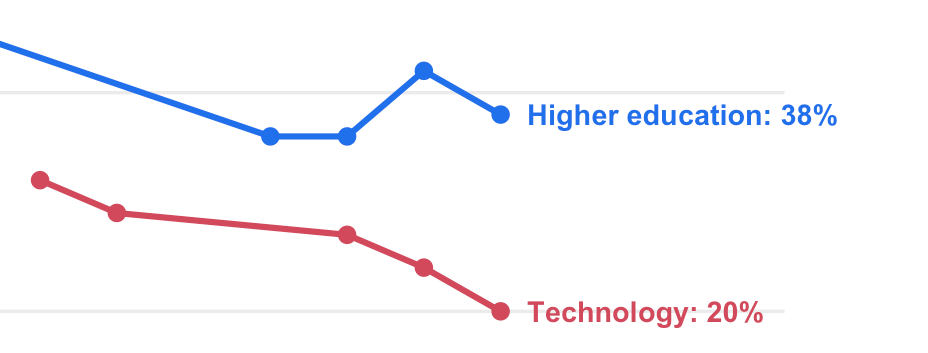
Technology is not the Solution to the Crisis of Confidence in Higher Education
Current Affairs
,
Politics
,
Teaching
July 27, 2026
The Latest
AI Generated Maps of Southeast Asia Are Here
June 11, 2026
Agentic AI and Social Science Research Practice
January 23, 2026
Measuring the Credibility Revolution in Political Science
December 3, 2025
Comparative Politics Needs Area Studies, and Area Studies Needs Comparative Politics
October 15, 2025
Investor Update – Strategic Learnings from The Political Economy of Shitcoins
August 29, 2025
Cryptocurrencies and the Political Economy of Money
August 8, 2025
More posts
Gen AI Draws Terrible Maps of Southeast Asia
August 5, 2025
State and Society in an Era of Backsliding
July 23, 2025
Building a new capital city is popular—paying for it is not
June 6, 2025
Teaching and Democracy in America
June 2, 2025
The Institutions Are Held Together by Values
April 2, 2025
Deep Civil Society and Collective Action
March 21, 2025
Everyday Authoritarianism is Maddening and Stupid
February 16, 2025
Generative AI Weighs in on Current Events: Eric Adams Edition
February 14, 2025
Science and International Studies are the Foundation of American Power
February 4, 2025
We Kneel to No Pope, and We Kneel to No King
January 22, 2025
1
2
3
…
259
Next Page
Subscribe
Subscribed
Tom Pepinsky
Join 377 other subscribers
Sign me up
Already have a WordPress.com account?
Log in now.
Tom Pepinsky
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar
Notifications