
The “credibility revolution” has transformed how social scientists think about the relationship between causal inference and statistical estimation. An active research agenda has developed over the past twenty years that seeks to reground or reformulate existing statistical models as treatment effects estimators, and Angrist and Pischke’s Mostly Harmless Econometrics is an early progress report.
Nevertheless, there are many more statistical models than there are derivations of treatment effects estimators associated with them. Treating a standard statistical model as a plug-and-play extension of a related model that does have treatment effects interpretations can be particularly dangerous. This post discusses an example.
My use of “plug-and-play” comes from my experience using standard statistical software. Once you realize that you have a dependent variable that requires a nonlinear model, nothing stops you from replacing (in Stata) reg Y X ... with (say) logit Y X .... Interpreting the results requires a bit more work, but the regression output looks about the same, and all too rarely do we actually interpret the substantive results (or care about the specificities of that interpretation). So for better or for worse, it is common to treat these as plug-and-play models. Just plug in the nonlinear model that fits your dependent variable and off you go.
The context of my example is the linear difference-in-differences model, where one compares the changes in a group that experienced a change between t1 and t2 with a group that did not experience such a change. The standard linear regression-based formulation of the model is
with G = group (treated or not), T = time (before and after the treated group got the treatment), and X are controls. The model relies on the assumption that the trend between periods in the treated group is the same as that in the control group. The model below (from Wikipedia) shows why such an assumption is commonly called “parallel trends.”

One convenient feature of the regression-based implementation of the diff-in-diff model is that the coefficient 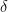

Now, interaction terms in general have proven troublesome for applied researchers basically forever (cavepeople were omitting constituent terms back in the Neolithic, which is why it took so long to discover that fire required fuel and heat). But in nonlinear models they are especially challenging. Most notably, in 2003 Ai and Norton (PDF) reminded applied researchers that in nonlinear models like logit and probit, the marginal effect of an interaction term is not the same as the interaction effect. They can have different magnitudes, different levels of statistical significance, even different signs. Interaction terms in the nonlinear models cannot be interpreted as they can be as in linear models.
So what if one is interested in estimating treatment effect using a nonlinear diff-in-diff model? Say, the effect of a policy change on whether individuals attend college or not. The plug-and-play extension of the above linear regression specification will require an interaction term, just as the standard diff-in-diff model does.
It would seem that the Ai and Norton conclusions ought to extend perfectly: if the same statistical model is being used, then shouldn’t the same interpretations of interaction terms follow? However, Puhani (PDF) demonstrates that this is not true.

How? Why? Puhani and also Lechner (PDF) provide extended discussions, but the core reason is that causal effects must be defined differently when bounding the dependent variable because potential outcomes too must be bounded. One consequence, as Puhani discusses, is that
The takeaway from this discussion is that the very same statistical model must be interpreted differently when used to identify treatment effects versus summarizing partial correlations. Plug-and-play statistical models are generally dangerous in a treatment effects world. This is perhaps a further reason that many are skeptical of logit or probit as alternatives to OLS—not because the differences don’t usually matter, but because treatment effects interpretations of nonlinear models might not be obvious. The real work is in determining the conditions under which plug-and-play models are appropriate, something which new research (which uses the terminology of “plug-in estimators”) promises to do.
