A recent report from Gallup shows that Americans’ confidence in institutions continues to be near its all-time low. Examining public opinion data from the past four decades, we see that confidence in all institutions has declined steadily since the mid-2000s.
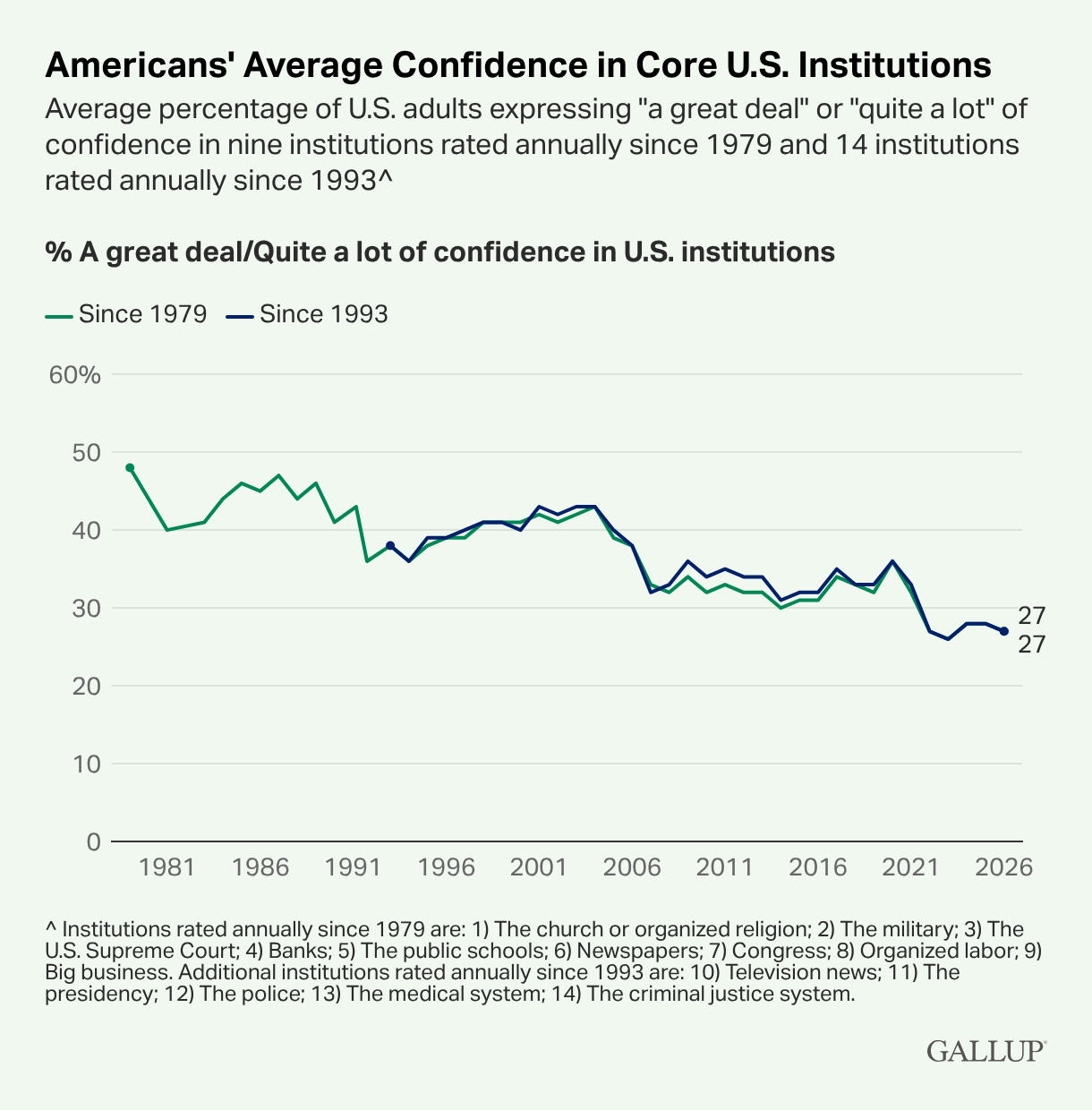
Visual inspection suggests that the decline dates roughly to the second Gulf War in (2003-2004 or so), but interocular tests are notoriously unreliable. There is surely more work to be done to decompose this series into its trends, intercept-shifts, and noise.
As Mark Copelovitch has noted on Bluesky, these data are important background context for the widely-noted “crisis of confidence in higher education” (see also here and here and here and so on and so forth). It is one thing if higher education is facing a lack of public confidence but other American institutions remain popular. It is quite another thing if all American institutions are facing a crisis of confidence, and higher education is just one among many.
Buried in the links of the Gallup report are data on two institutions of particular interest to me: higher education and large technology companies. As a higher education professional, I have good reasons to follow public perceptions of this sector, and I am also quite attuned to the cacophony of voices who insist that technology is going to revolutionize—or undermine, or fix, or transform, or displace—the sector entirely. Happily, Gallup makes its raw data avaiable to the public, which allows me to put together this figure.
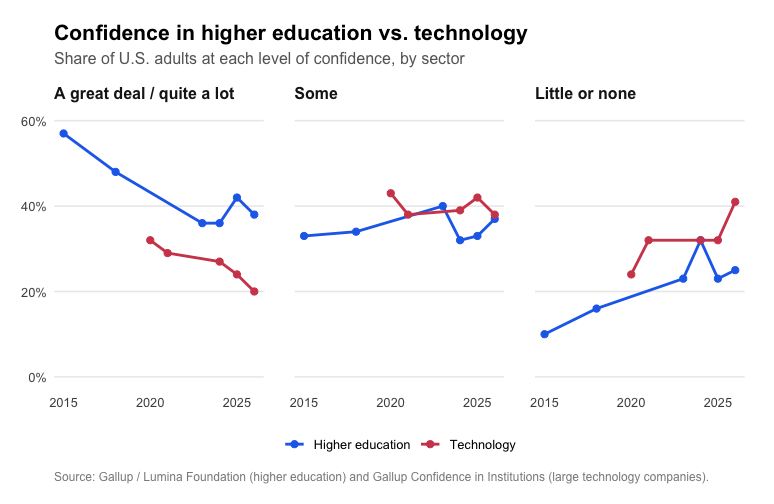
The sector-specific results mirror the overall trends identified above: public confidence in higher education is declining rapidly, surely a worrisome trend if you are someone in, to quote Tom Lehrer, the “ed biz.” But American have even less confidence in large technology companies. And that gap appears to be widening in the most recent surveys.
These results should lead higher education leaders and administrators to think carefully about what the crisis in public confidence in higher education really means and how best to respond to it. If you think that the crisis in confidence in higher education requires a solution, then it is hard to argue that embracing technology is an effective response to that crisis, because the companies that manufacture and market that technology are even less popular than higher education is. It is foolish to embrace EdTech in 2026 if the goal is to regain the public’s trust.
Speaking in my individual capacity, my own view is that the crisis of confidence in higher education does not have an immediate solution. The problems are systemic, they are general features of American public life that cannot be solved by committees, reports, or public relations campaigns. The “solution” to the crisis in public confidence in higher education is to focus on principles, values, and the mission of higher education. I will have more to say on that in the coming months, but my cantankerous take is that it’s time to put mission ahead of metrics. Become unmeasureable, and never apologize for it.
But for now, as always, a good rule of thumb is: there are no technological solutions to political problems. Anyone who insists there is a technological solution to something like a public crisis of confidence in higher education is probably trying to sell you that technology. And Americans have grown weary of the promises of the technology companies, both in the higher education space and more broadly.
One wonders why the pundits and higher education commentariat have so thoroughly missed the vibe shift. Is it because they, too, are trying to sell us something?