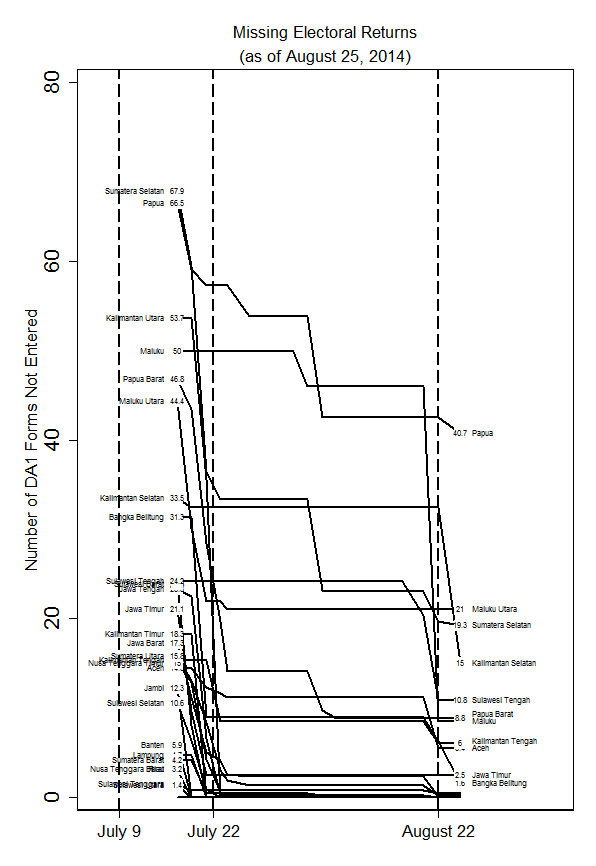
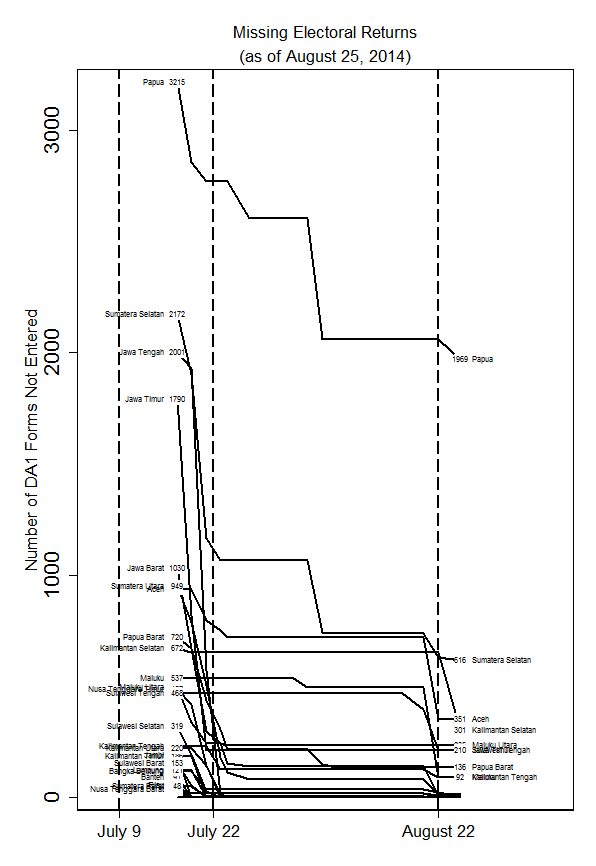
I am 100% fascinated by this post by Jay Ulfelder on using text mining to code regime type. I love how it allows us to think concretely about fuzzy classifications, and to be explicit about uncertainty. If I had to guess, I’d say that this is the future of regime coding.
I was also a bit dismayed to see that some of my favorite countries score lower on a likelihood-of-democracy score than I would like.

What could explain why? Well, the one thing that we depend on in such exercises is an unbiased (or at least “randomly” biased) source of text. And it could be that there are features of countries that lead sources to discuss them differently. Let’s take an example: the killing of an unarmed black man by a police officer will almost certainly not affect the way that Freedom House discusses the United States. However, a police killing of an unarmed man in a country like Indonesia may affect the way that Freedom House discusses Indonesia. Same with violence against Sikhs in the U.S. versus violence against Christians, Ahmadis, and Shia in Indonesia. The list goes on.
Now, this need not undermine the exercise. My guess is one could model the differences in the way that the underlying texts represent political conditions in the countries that they cover using a rich set of observables. If we hypothesize that the sources talk about rich countries differently, they talk about Muslim countries differently, and they talk about countries with histories of authoritarianism differently (so that the authoritarian histories have “slow decays”), then perhaps that could be used as input to the classification algorithm. I don’t have access to the Ulfelder, Schrodt, and Ward paper, but I wonder if they’ve explored such issues.
One thing is for sure: I wish I could raise these questions myself at their presentation. Unfortunately, I am a discussant on a panel at the same time, at the always popular 8AM slot. So, I look forward to reading more.