
I had the opportunity to serve as a discussant for a panel on big data in Asian studies (abstracts in PDF) at the most recent meeting of the Association for Asian Studies. As it turns out, social media is one of the central sources of data for this rapidly developing new field (the other is machine coding of text). As I was thinking about how to discuss the various opportunities and challenges that come from using social media to study politics—and everyone involved was a political scientist of some sort—I found myself trying to sketch out a data generating process for social media data. I came up with four basic challenges that follow as a result of how I conceptualize this DGP.
The basic idea is that social media is a form of political participation. When you think about it that way, though, it’s immediately clear that it is only one of many forms of participation. We might share a link on Facebook, or retweet a hashtagged tweet, and that generates social media data. But we might also vote, or protest, or send a letter to a representative, which is also a form of participation, but one that is not observed in the social media data. There are lots of forms of political participation, and denote the collection of them as 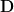


The first challenge, then, is characterizing the relationship between 

There is then a technology that censors some fraction of 


So the second challenge is characterizing
Next, recall that social media is social. That means that we care about other actors 

Third challenge is to characterize this recursive system in which actors participate in response to both online participation and offline participation, and the online participation is potentially censored.
And finally, we suspect that governments choose 

This fourth challenge is to characterize how governments deploy censorship in response to the anticipated consequences of social media as a form of political participation. Note in the final expression above that offline participation may change as a response to online censorship.
Put together this way, I find it much easier to think about the opportunities and challenges from using social media. It’s also useful to see important new contributions in terms of how they make sense of each of these challenges. King, Pan, and Roberts (2013), for example, addresses the fourth challenge particularly well.
